

In the search giant’s pursuit to offer more relevant results to its users, Google on February 10 announced that Passage Ranking is live for English queries in the U.S.
NB: This is an article from Milestone
As Google metaphorically stated, “Passage ranking will allow it to find the needle in the haystack,” bettering their quest to answer specific queries relevantly.
Subscribe to our weekly newsletter and stay up to date
What is Google Passage Ranking?
Using the SMITH (Siamese MultI-depth Transformer-based Hierarchical) algorithm, Google can now better understand passages within a webpage and will deliver more relevant results for specific long-tail queries. With SMITH in the frame, the big question on everyone’s mind surfaces – What about BERT?
In its recently published research paper, Google with no qualms, blatantly stated that its SMITH algorithm outperforms the BERT algorithm. This doesn’t mean the BERT algorithm is a thing of the past. While the BERT algorithm assists the search engine in understanding words and the context of sentences using entities or semantic SEO, the SMITH algorithm uses BERT as a diving board to understand sentences and paragraphs within a document. Addressing BERT’s shortcomings of being able to understand just the context of words in a sentence, SMITH goes for the home run to understand passages – the context of sentences strung to each other and their relevance to the query–hence passages.
Initially called passage-indexing, Google changed it to Passage Ranking to dampen any confusion, and rightly so. With the SMITH algorithm, Google will not index passages within a page independently but the indexing of a whole page continues, just that with SMITH, they can pick out good content buried in bad page structure – the “needle in the haystack”.
Let’s give you a simple example.
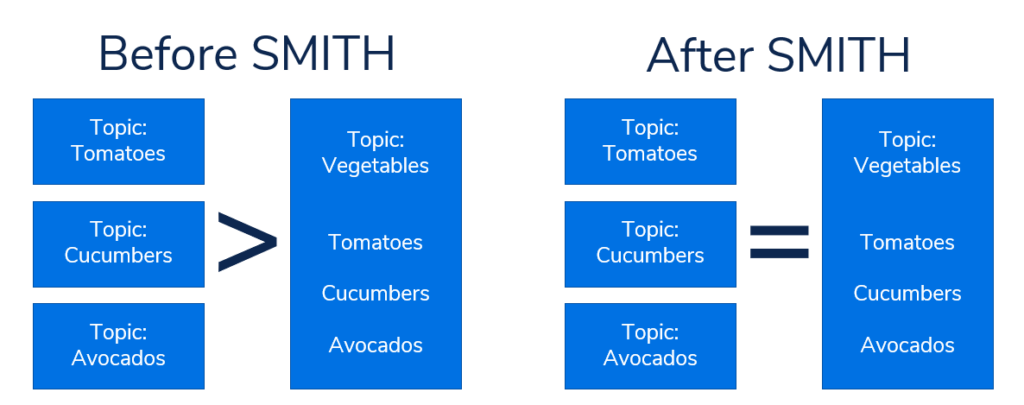
Let’s say that you made a query about “cucumbers.” Google would rank a page for cucumbers pretty highly because it understands the main entity/topic of the page is cucumbers and all the text below is supporting content for cucumbers. If a page contained multiple topics (tomatoes, cucumbers, avocados) then that page isn’t as specific/relevant to the search query so it would rank lower or not at all. With SMITH Google understands that even though a page contains multiple topics, a particular passage on this (relatively) badly structured page matches the search query very well and so it will rank the page as well as the page for Cucumbers only.
What you need to keep in mind following Google’s SMITH algorithm and Passage Ranking
We said this when Google announced the BERT algorithm, schemas – which offer entity recognition to influence Google Knowledge Graph – along with quality content is key. With Passage Ranking now live, the emphasis on quality content that answers specific questions or queries is a lot more profound. Following a good page structure with relevant and well-defined Titles and Header tags are still of importance to offer the right signals to the search engine. However, a reiteration, considering that BERT and SMITH algorithms are working in conjunction, the search engine will be relying on structured data (schemas) for facts and unstructured content (prose-type content on a webpage) as a selection criterion to deliver the most relevant result.
By moving into semantic search with BERT, Google jumped their biggest hurdle with its language-agnostic use of entities to collect world information. Using entities, irrespective of the language and no keyword dependency, the search engine can interpret and categorize web pages, establish relationships between entities (and therefore between web pages) and deliver better answers to questions for web users. This has allowed Google to personalize results based on the interest of users – reflected by their search history.
Now here’s where using structured data or schemas gives your page an advantage. At present, Google detects less than 20% of the entities present in the content published on the web. Using schemas, you are giving the search engine a direct signal to understand the content and the context of your page.
That said, implementing schemas on every web page could prove to be a meticulous process while ensuring that they are error-free requires constant auditing. To improve the trust factor of the schemas with the search engine and influence Knowledge Graph results, users can reference Wikipedia pages in their schema.



